Teaser
Note that we use fixed pretrained diffusion models without any fine-tuning or gradient guidance.

Diffusion models (DMs) synthesize high-quality images in various domains. However, controlling their generative process is still hazy because the intermediate variables in the process are not rigorously studied. Recently, the bottleneck feature of the U-Net, namely $h$-space, is found to convey the semantics of the resulting image. It enables StyleCLIP-like latent editing within DMs. In this paper, we explore further usage of $h$-space beyond attribute editing, and introduce a method to inject the content of one image into another image by combining their features in the generative processes. Briefly, given the original generative process of the other image, 1) we gradually blend the bottleneck feature of the content with proper normalization, and 2) we calibrate the skip connections to match the injected content. Unlike custom-diffusion approaches, our method does not require time-consuming optimization or fine-tuning. Instead, our method manipulates intermediate features within a feed-forward generative process. Furthermore, our method does not require supervision from external networks. The code is available at this link.
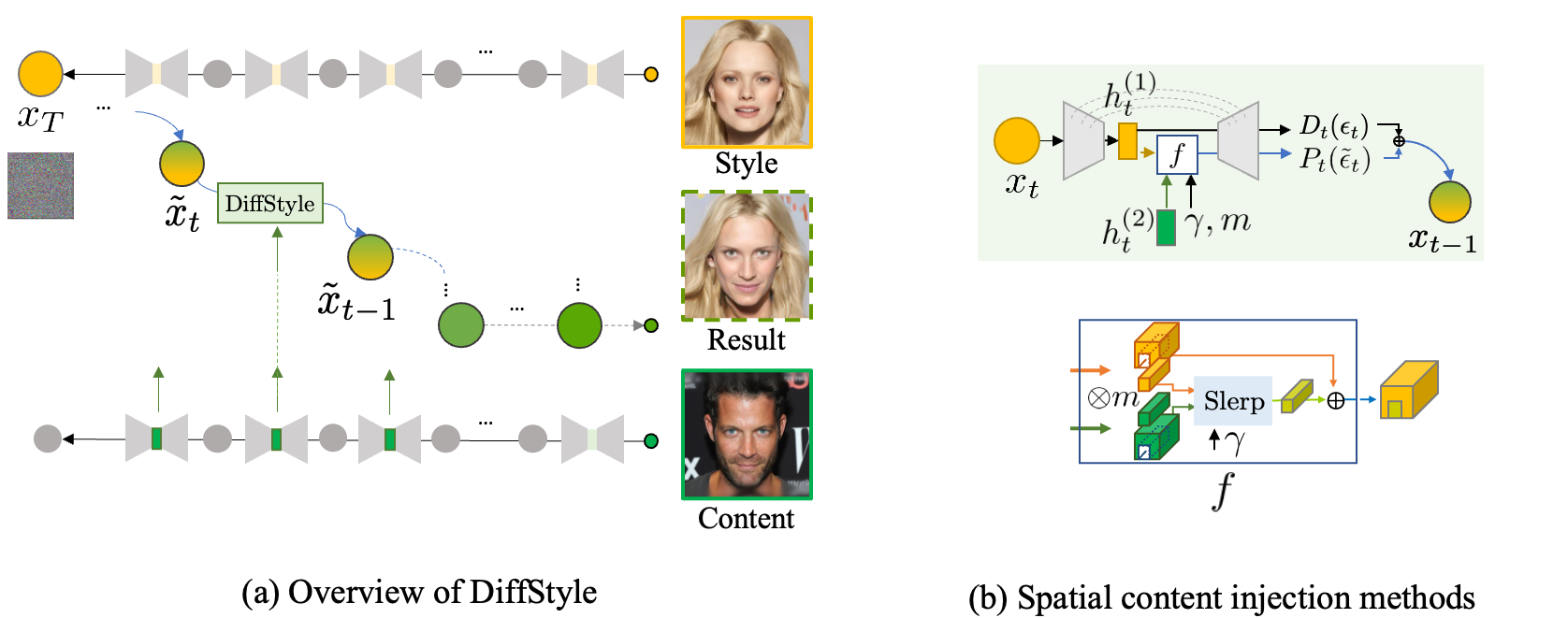
(a) Overview of InjectFusion. During the content injection, the bottle neck feature map is recursively injected during the sampling process started from the inverted $ x_T $ of style images. The target content is reflected into the result image while preserving the original style elements. (b)
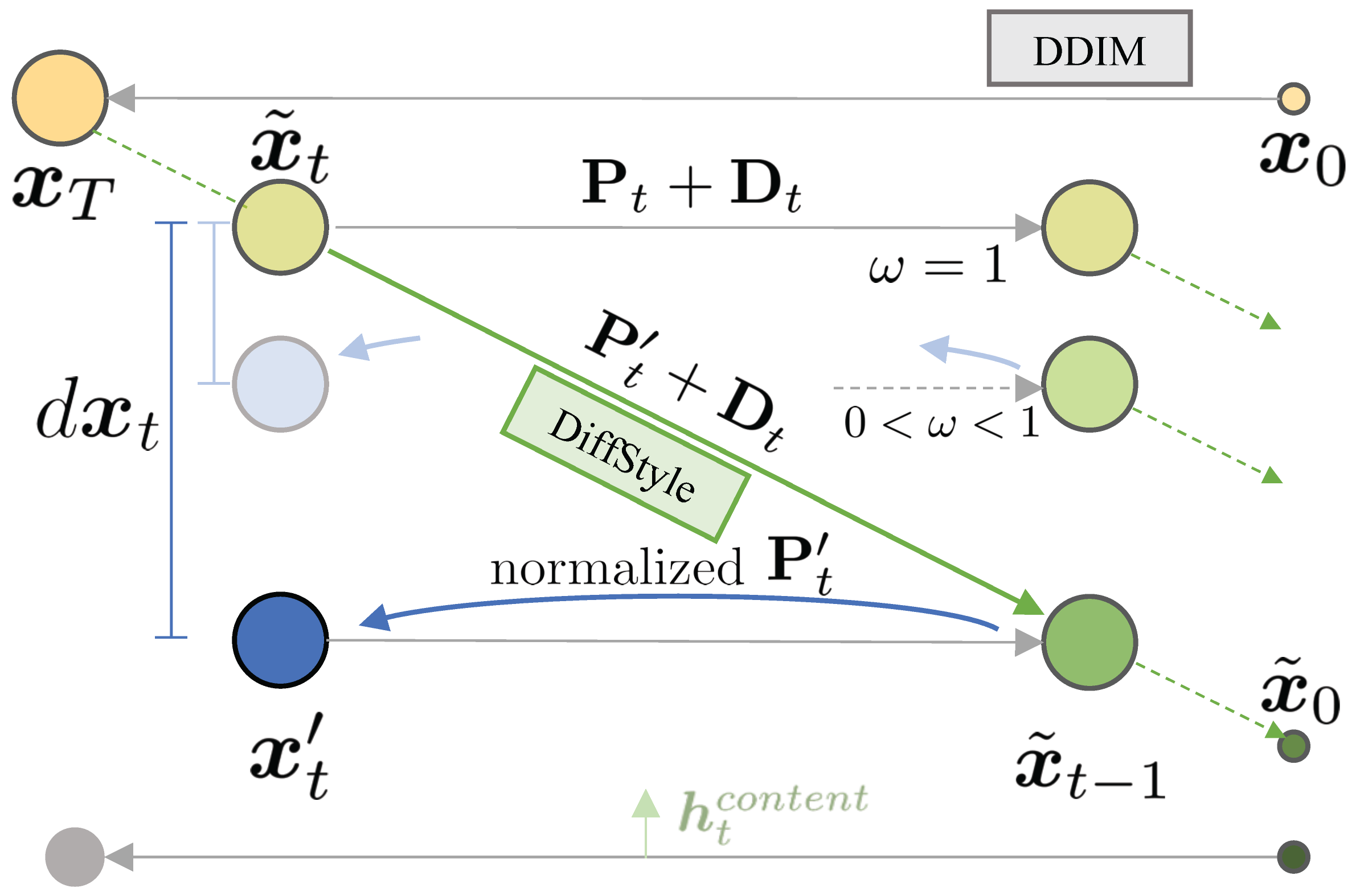
Style calibration. The result of DDIM reverseprocess with given approximated $x′_t$ may be similar to the result of a corresponding injected result $ \tilde{x}_{t−1}$. When the closer ω gets to 1, the more style elements are added through $ dx_t $. Note that the effect of style calibration is different from modifying $ γ $ because it remains predicted x0 by solving the DDIM equation






























© This webpage was in part inspired from this template.