Research
Advancing the frontiers of AI-powered video localization through cutting-edge research
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
CineLingo Research Team • Seoul, South Korea
1Abstract
The intrinsic link between facial motion and speech is often overlooked in video localization, where lip-sync, text-to-speech (TTS), and visual text translation are typically addressed as separate tasks. This paper introduces CineLingo, a unified framework to simultaneously synthesize and condition on both facial motion, speech, and visual elements for seamless video localization.
Our approach leverages advanced AI models and a novel Multi-Modal Localization Transformer (MM-LT) architecture, integrating specialized Lip-Sync, TTS, and Visual Translation modules. These are coupled via selective joint attention layers and incorporate key architectural choices, such as temporally aligned positional embeddings and localized joint attention masking, to enable effective cross-modal interaction while preserving modality-specific strengths.
Trained with an end-to-end objective, CineLingo supports a wide array of conditioning inputs—including text, reference audio, and reference motion—facilitating tasks such as synchronized talking head generation from text, audio-driven animation, automated dubbing, and much more, within a single, coherent model. CineLingo significantly advances multi-modal generative modeling by providing a practical solution for holistic video localization.
2Architecture
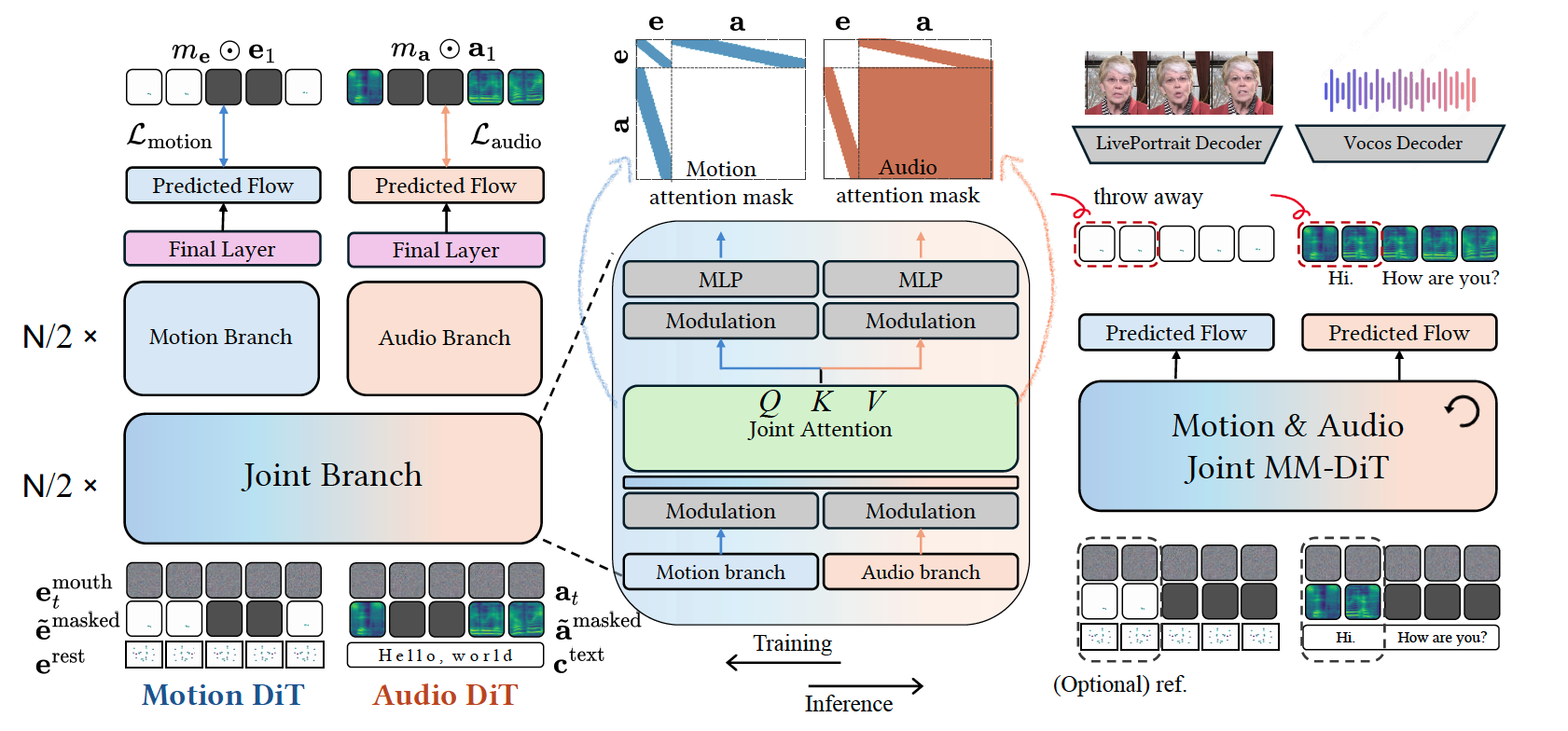
The training and inference pipeline of the JAM-Flow framework. Our joint MM-DiT comprises a Motion-DiT for facial expression keypoints and an Audio-DiT for mel-spectrograms, coupled via joint attention. The model is trained with an inpainting-style flow matching objective on masked inputs and various conditions (text, reference audio/motion). At inference, it flexibly generates synchronized audio-visual outputs from partial inputs.
TTS-CtrlNet: Time varying emotion aligned text-to-speech generation with ControlNet
CineLingo Research Team • Seoul, South Korea
1Abstract
Recent advances in text-to-speech (TTS) have enabled natural speech synthesis, but fine-grained, time-varying emotion control remains challenging. Existing methods often allow only utterance-level control, require full model fine-tuning with a large emotion speech dataset, which can degrade performance.
Inspired by ControlNet for text-to-image generation, we propose the first ControlNet-based approach for controlling flow-matching TTS (TTS-CtrlNet), which freezes the original model and makes a trainable copy of it to process additional condition. We show that TTS-CtrlNet can boost the pretrained large TTS model by adding intuitive, scalable, and time-varying emotion control while inheriting the ability of the original model (e.g., zero-shot voice cloning & naturalness).
Furthermore, we provide practical recipes for adding emotion control: 1) optimal architecture design choice with block analysis, 2) emotion-specific flow step, and 3) flexible control scale. Experiments show that TTS-CtrlNet can effectively adds an emotion controller to existing TTS, and achieves state-of-the-art performance with emotion similarity scores: Emo-SIM and Aro-Val SIM.
2Architecture
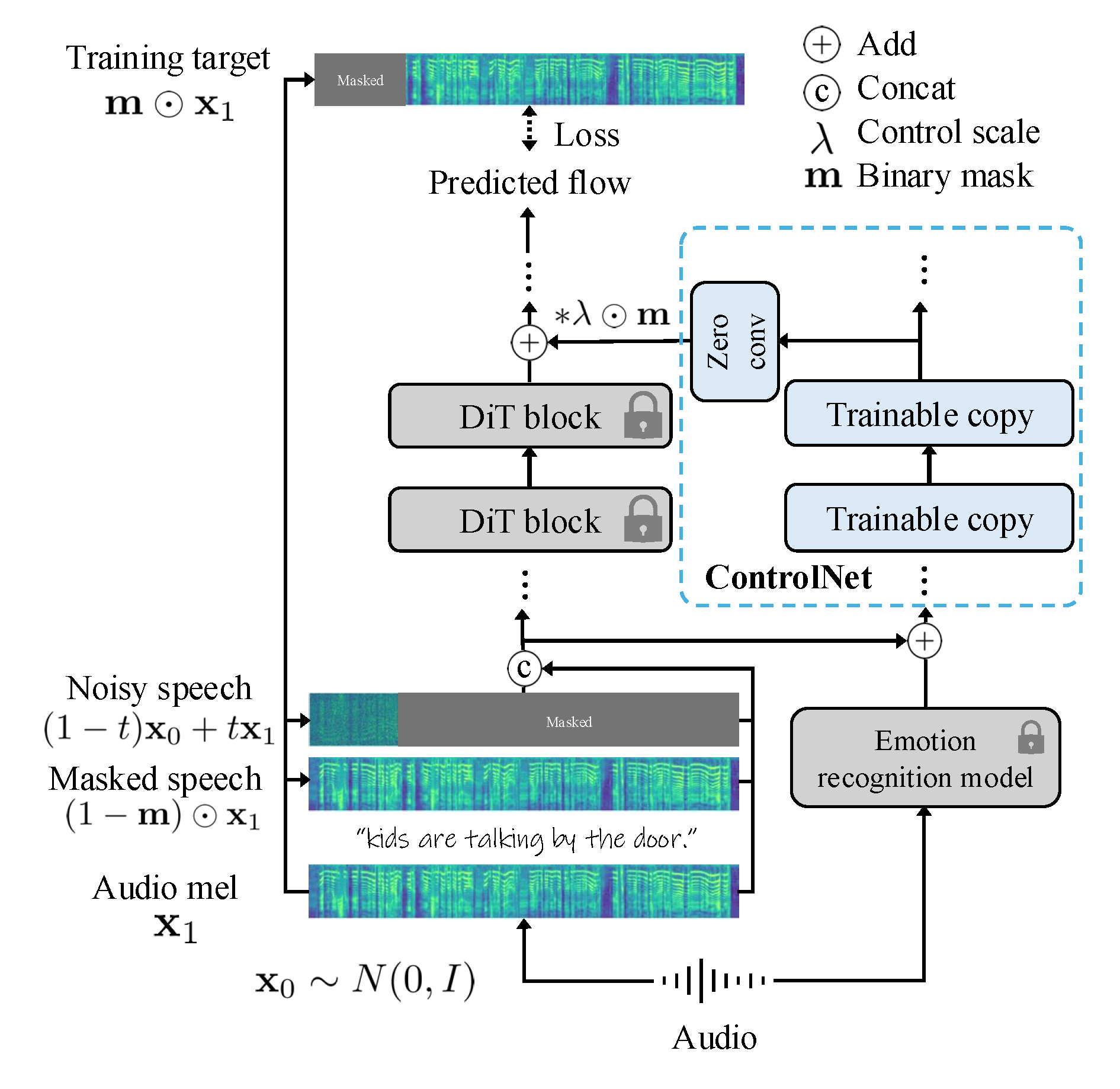
The training and inference pipeline of the TTS-CtrlNet framework. Controlling signal is processed through ControlNet and fed into the subset of blocks in original model.
Our Research Areas
We focus on four key areas that form the foundation of our video localization technology
Agent-based Translation
We use AI agents to perform high-quality, context-aware translation that adapts to content genre, tone, and culture. Our agents understand the broader context of the content and make intelligent decisions about localization strategies.
Text-to-Speech (TTS)
Our custom TTS systems produce native-level voices tailored to tone, timing, and character consistency. We leverage large language models and advanced audio synthesis to create voices that sound natural and culturally appropriate.
Lip-sync Modeling
We build models that align facial movements with translated speech — frame-accurate and emotion-preserving. Our approach uses advanced computer vision and speech synthesis to ensure that every lip movement matches the spoken words naturally.
On-Screen Text Translation
Combining inpainting with vision-language models, we reconstruct visual text to deliver seamless translations. Our system can detect, translate, and replace text in videos while maintaining visual coherence and readability.
Join us
If you're excited about building the most natural, delightful, and culturally sensitive video localization systems out there, reach out—we're hiring.