TTS-CtrlNet: Time varying emotion aligned text-to-speech generation with ControlNet
Paper
PaperAbstract
Recent advances in text-to-speech (TTS) have enabled natural speech synthesis, but fine-grained, time-varying emotion control remains challenging. Existing methods often allow only utterance-level control, require full model fine-tuning with a large emotion speech dataset, which can degrade performance. Inspired by Zhang et al. (2023), we propose the first ControlNet-based approach for controlling flow-matching TTS (TTS-CtrlNet), which freezes the original model and makes a trainable copy of it to process additional condition. We show that TTS-CtrlNet can boost the pretrained large TTS model by adding intuitive, scalable, and time-varying emotion control while inheriting the ability of the original model (e.g., zero-shot voice cloning & naturalness). Furthermore, we provide practical recipes for adding emotion control: 1) optimal architecture design choice with block analysis, 2) emotion-specific flow step, and 3) flexible control scale.
Experiments show that ours can effectively adds an emotion controller to existing TTS, and achieves state-of-the-art performance with emotion similarity scores: Emo-SIM and Aro-Val SIM.
Architecture
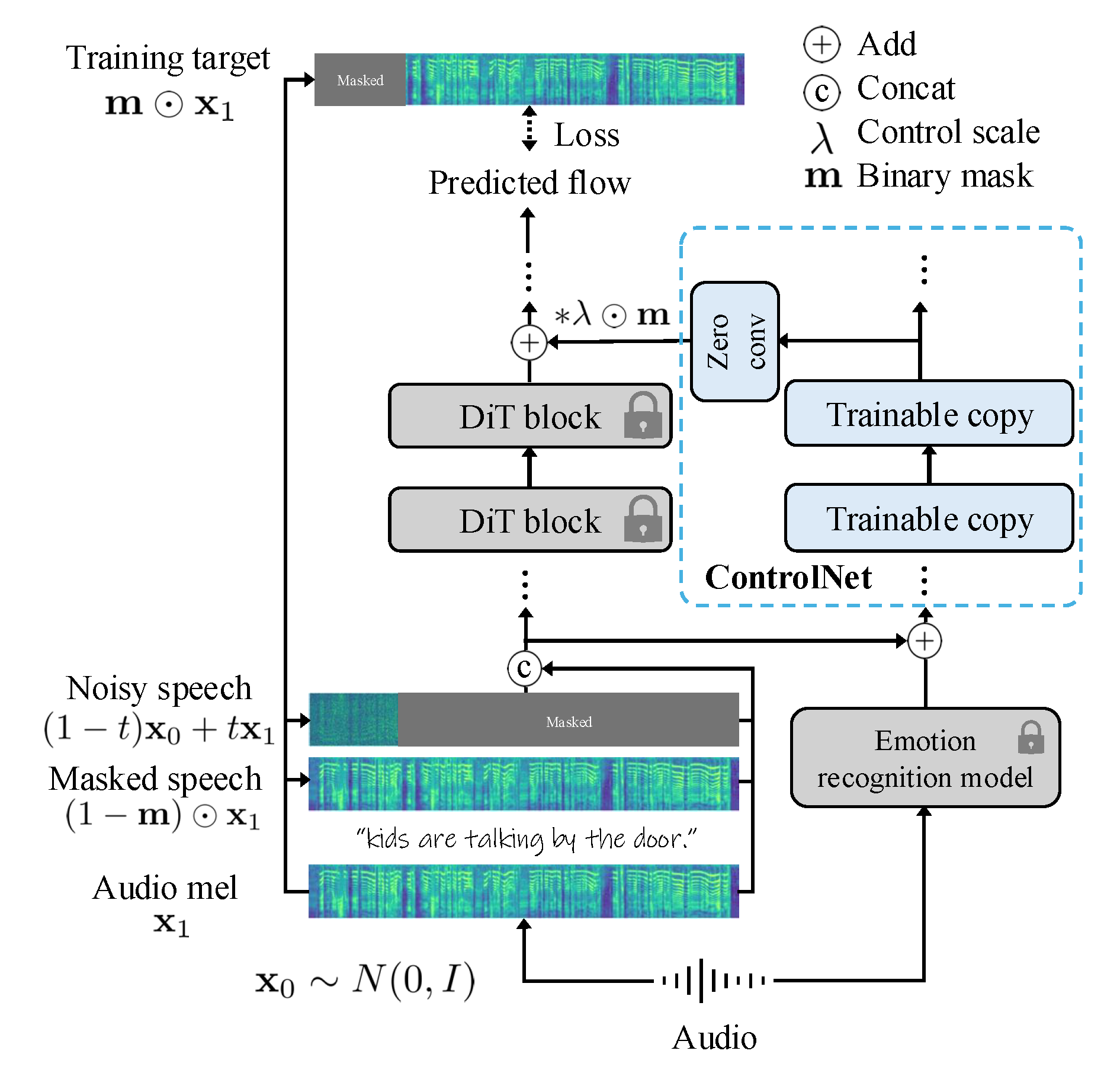
Overview of TTS-CtrlNet: Controlling signal is processed through ControlNet and fed into the subset of blocks in original model.
EMO-Change
A reference audio was constructed by concatenating two speech samples, each expressing a different emotion, to explicitly include multiple emotional cues within a single utterance.
JVNV S2ST
Japanese-to-English speech-to-speech translation